[EC2] 로드 밸런서 장애 대처 실습
in Infrastructure on AWS, Loadbalancing
로드 밸런싱 장애 대처
실제로 AWS에서 제공하는 로드밸런서가 어떤 식으로 장애에 대처하는 지 확인해보도록 하자.
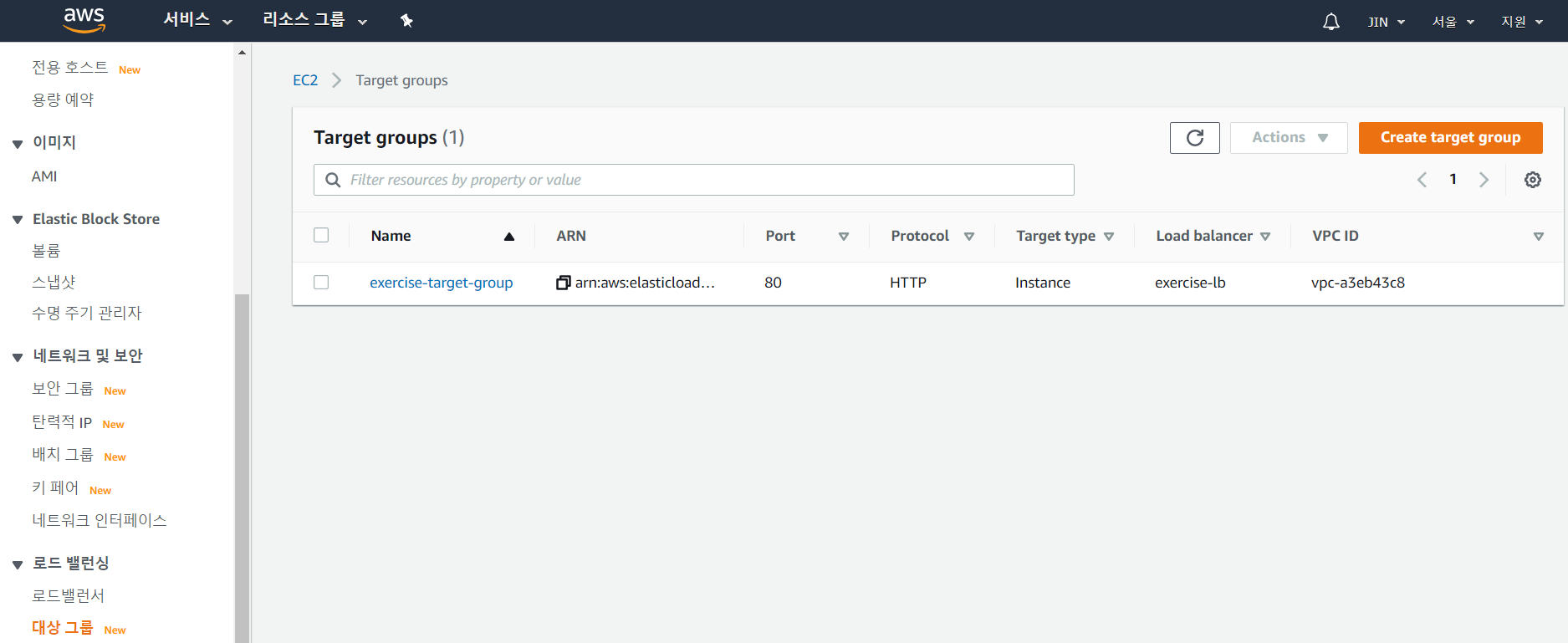 좌측 메뉴에서 로드밸런싱 -> 대상 그룹을 클릭하고 생성한 그룹 명을 클릭한다.
좌측 메뉴에서 로드밸런싱 -> 대상 그룹을 클릭하고 생성한 그룹 명을 클릭한다.
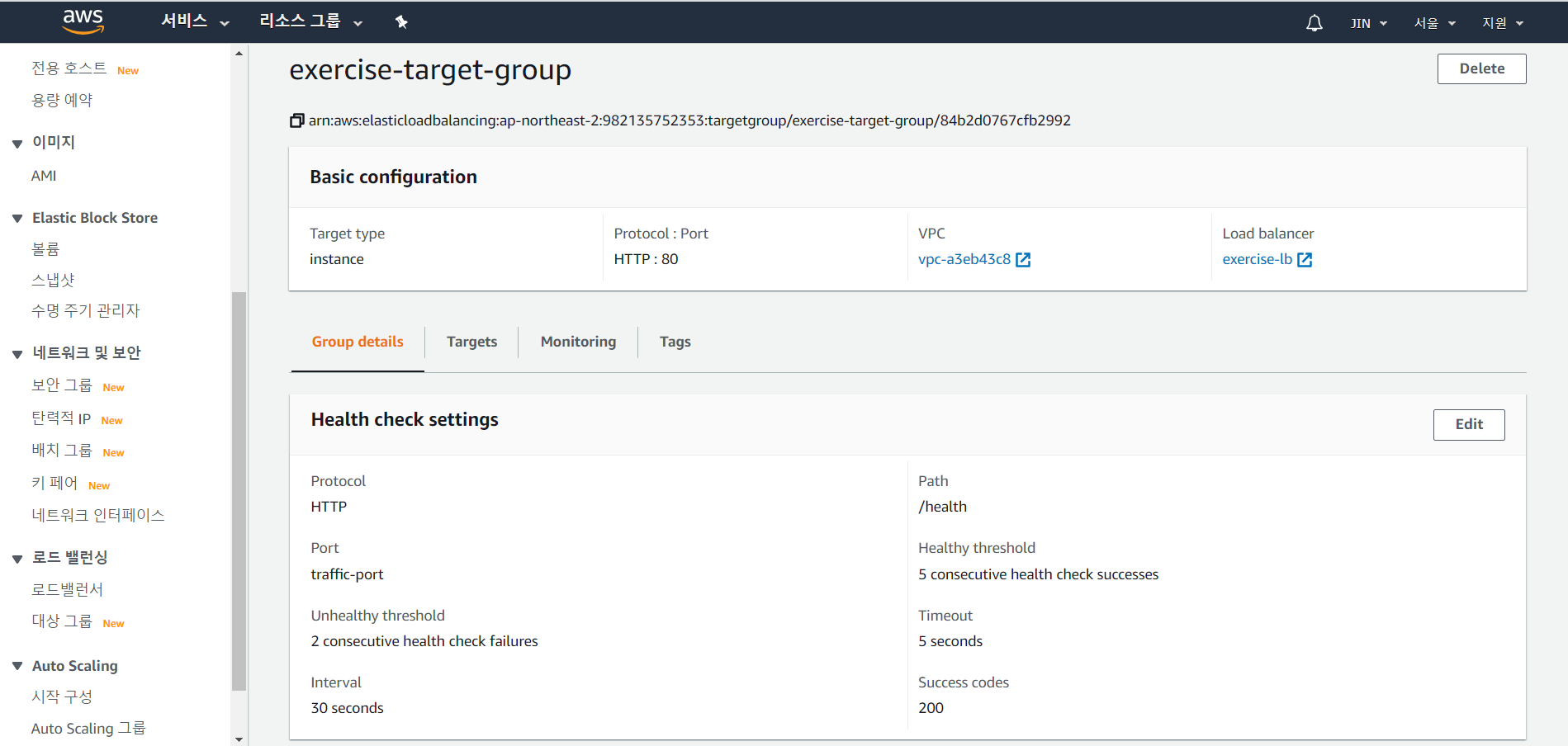 그룹명을 선택하면 위의 그림과 같은 화면이 나온다.
그룹명을 선택하면 위의 그림과 같은 화면이 나온다.
그러면 Group details를 클릭하고 edit를 클릭한다.
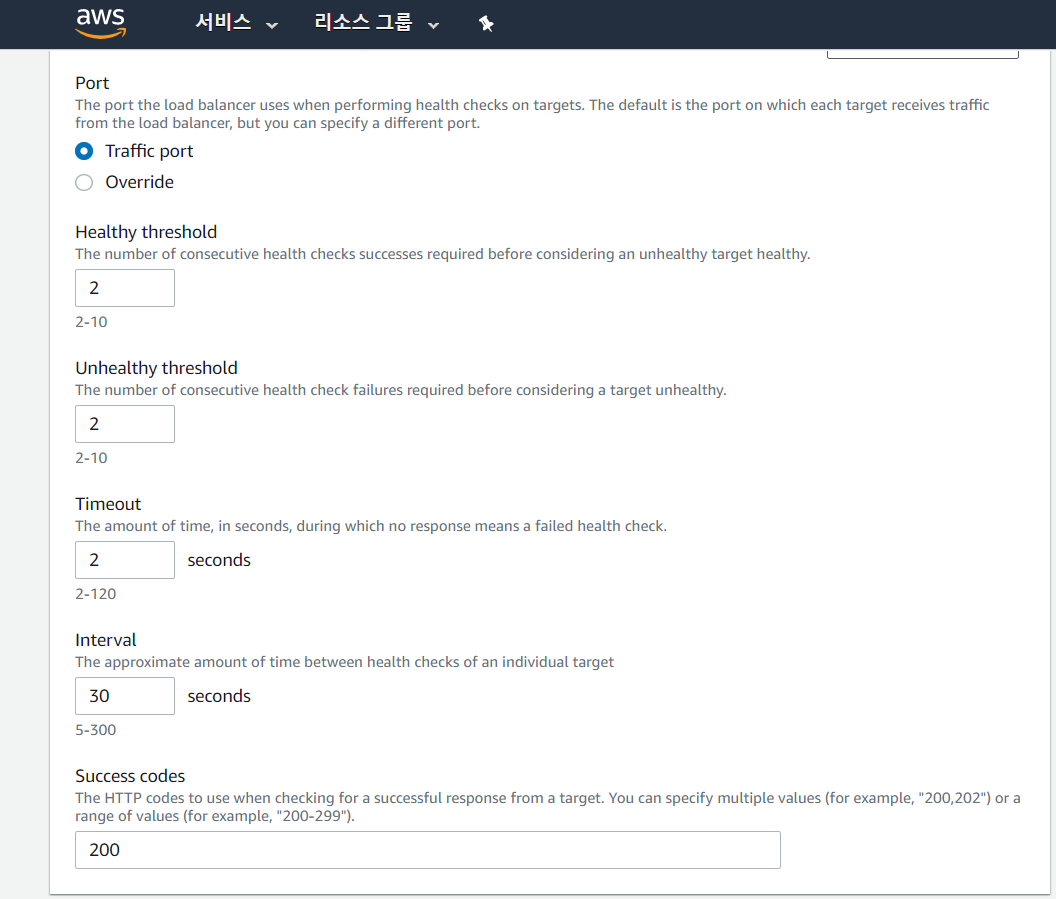 그리고 설정을 위와 같이 맞춰준다.
그리고 설정을 위와 같이 맞춰준다.
Healthy threshold, Unhealthy threshold, Timeout를 모두 2로 설정
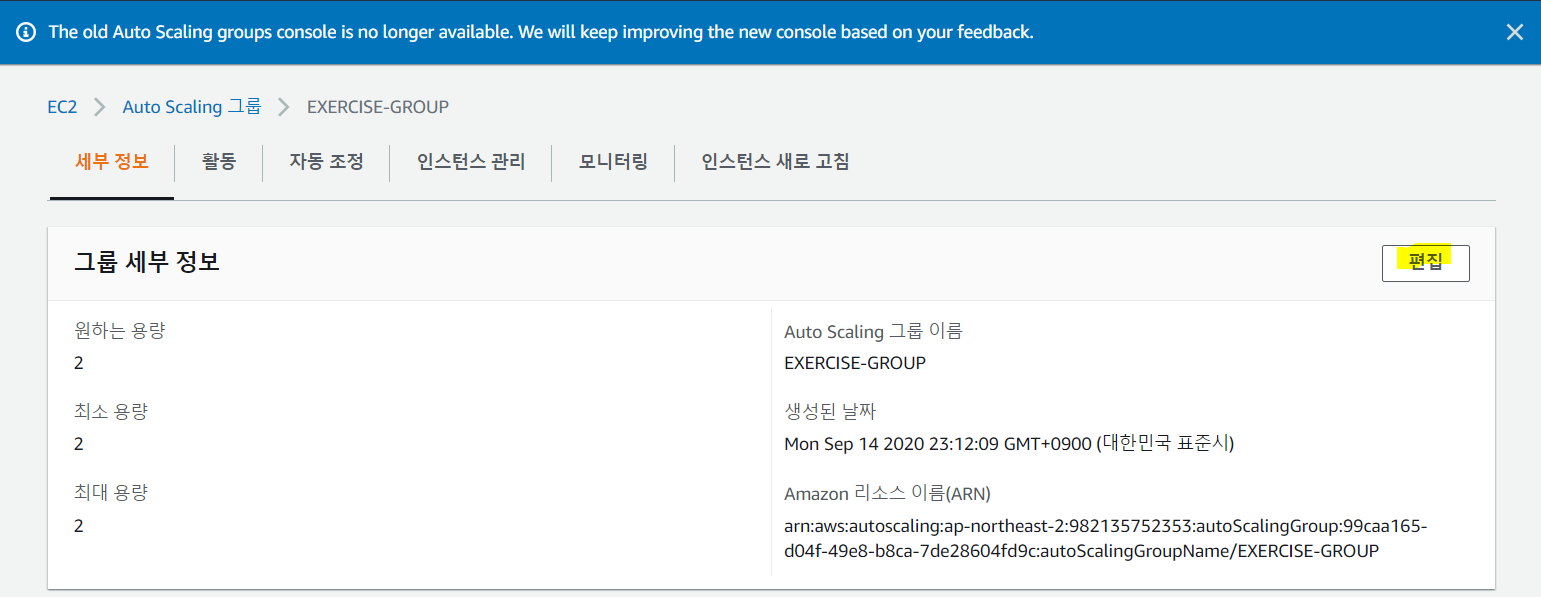 좌측의 Auto Scailing -> Auto Scailing 그룹에서 Exercise-group을 선택한 뒤 세부정보의 편집 버튼을 누른다.
좌측의 Auto Scailing -> Auto Scailing 그룹에서 Exercise-group을 선택한 뒤 세부정보의 편집 버튼을 누른다.
그리고 그림과 같이 원하는 용량, 최소용량, 최대용량을 모두 2로 맞춰준다.
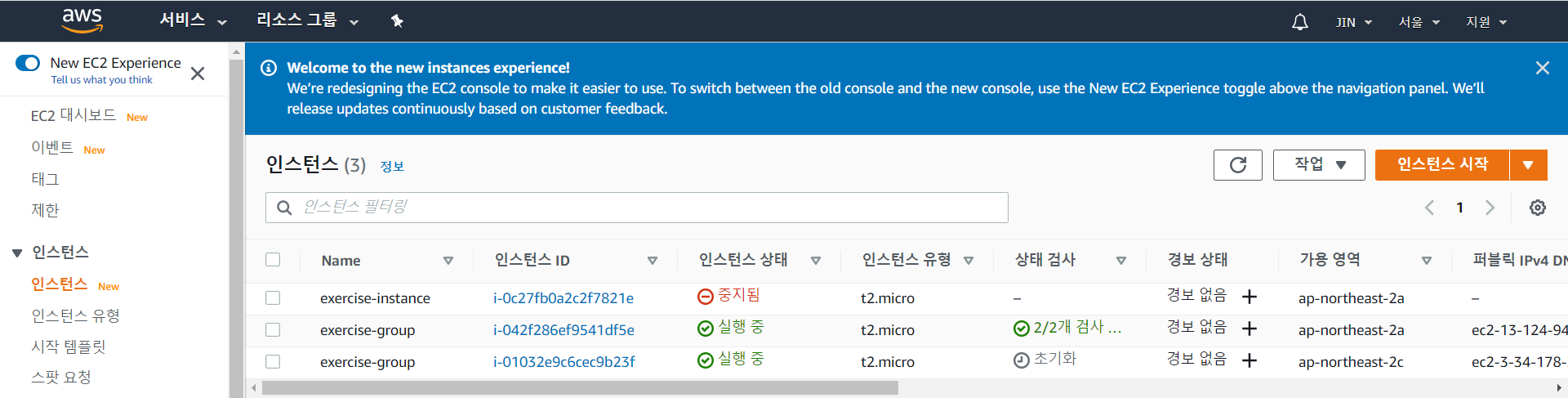 좌측의 인스턴스를 클릭한 후 생성된 인스턴스가 정상적으로 작동하는 지 확인한다.
좌측의 인스턴스를 클릭한 후 생성된 인스턴스가 정상적으로 작동하는 지 확인한다.
그리고 각각의 퍼블릭 IPv4 주소를 통해서 PuTTY를 통해서 SSH접속을한다.
nginx 접속 로그를 확인하기 위해 다음과 같은 코드를 입력한다.
$cd /opt/nginx/logs
$tail -f access.log
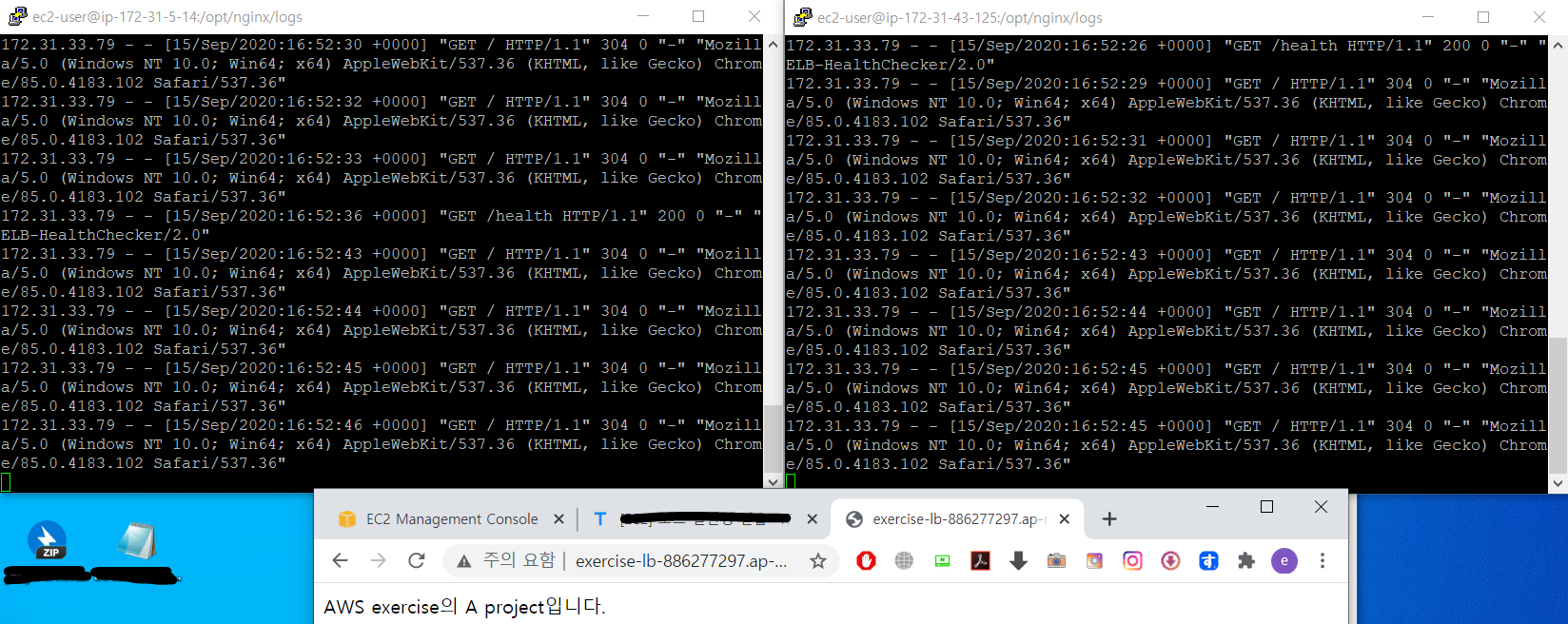 위의 코드를 입력하면 위의 그림과 같이 실시간으로 쌓이고 있는 로그를 확인할 수 있다.
위의 코드를 입력하면 위의 그림과 같이 실시간으로 쌓이고 있는 로그를 확인할 수 있다.
그리고 브라우저를 여러번 새로 고침해보면 양쪽의 로그가 골고루 쌓이는 것을 확인할 수 있다.
장애 상황을 재현하기 위해 한 쪽 서버를 서버스 중지한다.
$ sudo service nginx stop
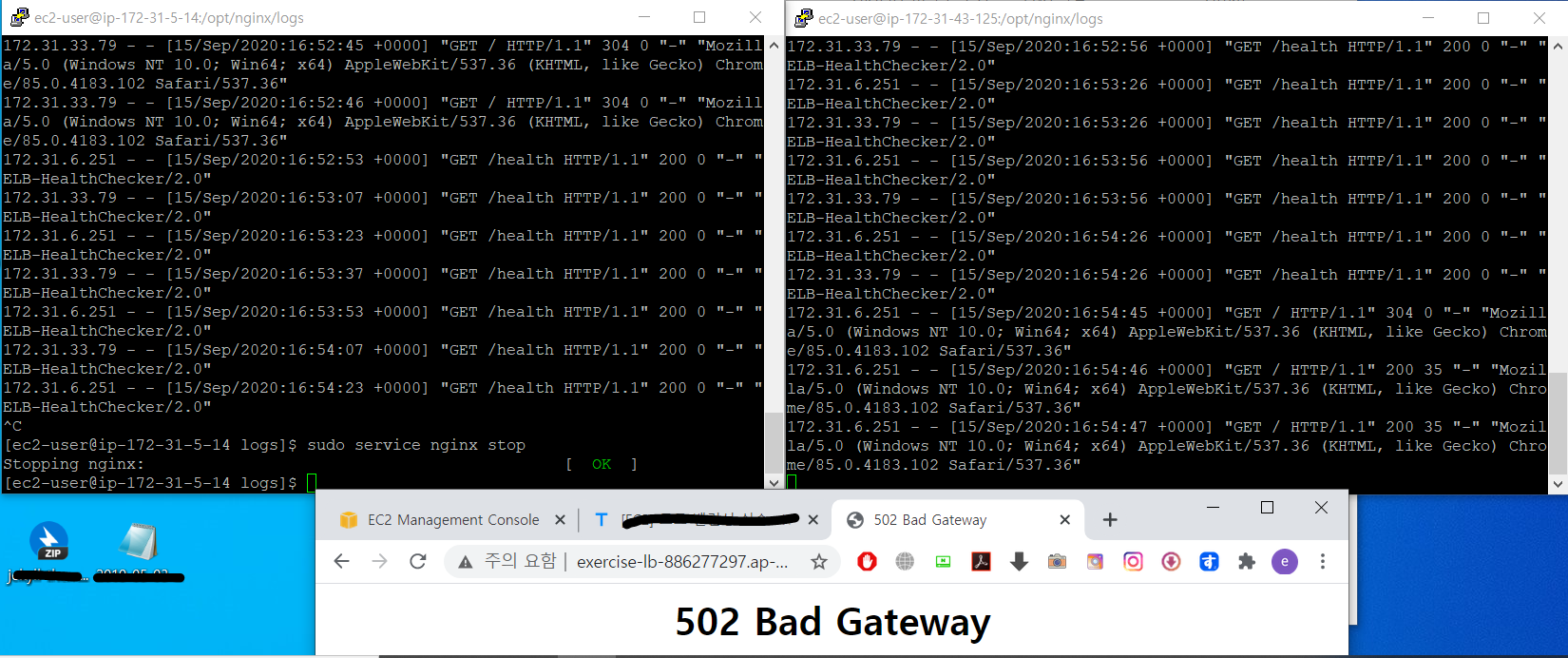 로드 밸런서가 장애가 일어난 것을 확인 하기 전까지는 브라우저를 여러번 새로고침하면 서비스가 종료된 페이지는 502에러를 띄운다. (서비스를 종료하지 않은 서버는 그대로 나옴)
로드 밸런서가 장애가 일어난 것을 확인 하기 전까지는 브라우저를 여러번 새로고침하면 서비스가 종료된 페이지는 502에러를 띄운다. (서비스를 종료하지 않은 서버는 그대로 나옴)
하지만 약간의 시간이 지난 후 새로고침을 연속으로 해보면 정상동작하는 서버로만 접속이 되는 것을 확인할 수 있다.
이를 통해 로드밸런서는 폴트 톨러런스(fault tolerance)기능도 한다는 것을 확인할 수 있다.
